Google hat vor kurzem die stabile Version von Gemini 2.5 Flash-Lite vorgestellt, die als leistungsoptimiertes, budgetfreundliches Arbeitstier für Entwickler konzipiert ist, die KI-gesteuerte Tools in großem Umfang entwickeln. Dieses Modell zielt darauf ab, einen großen Wert zu liefern – intelligent, schnell und erschwinglich – und ist damit ideal für Echtzeitanwendungen und kostenbewusste Teams.
⚙️ Warum Gemini 2.5 Flash-Lite wichtig ist
Geschwindigkeit für Erlebnisse in Echtzeit
Google positioniert Flash-Lite als das schnellste Modell der 2.5er-Serie und meldet deutlich geringere Latenzzeiten als frühere Versionen wie 2.0 Flash und 2.0 Flash-Lite. Diese Reaktionsfähigkeit macht es perfekt für Live-Übersetzungen, Chatbots und zeitkritische Interaktionen, bei denen selbst Verzögerungen von weniger als einer Sekunde die Nutzer frustrieren können.
Elite-Wert
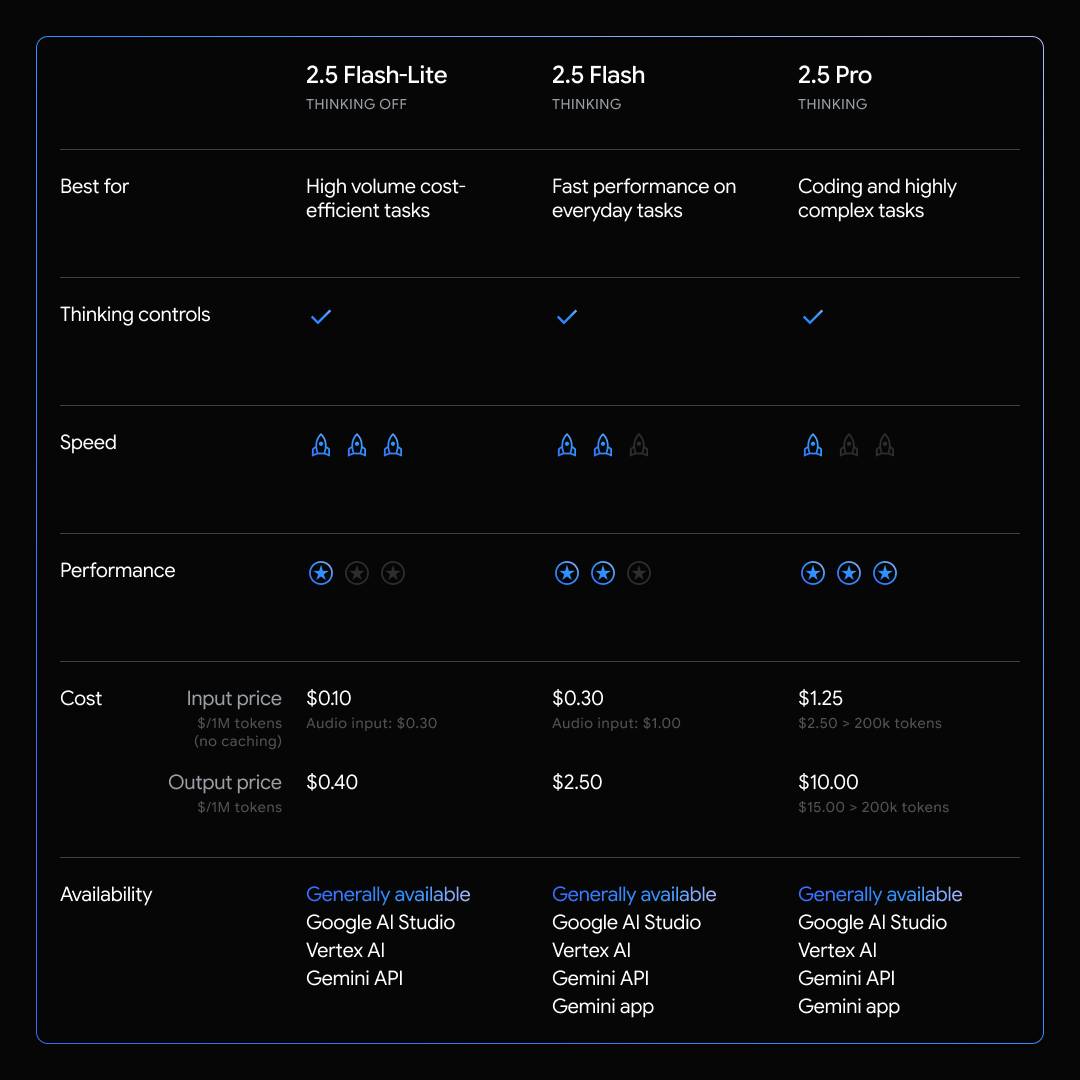
Mit einem Preis von nur 0,10 US-Dollar pro Million Input-Token und 0,40 US-Dollar pro Million Output-Token bietet Flash-Lite außergewöhnliche „Intelligenz pro Dollar“. Diese Preisgestaltung ermöglicht es Entwicklern, die Nutzung von API-Aufrufen nicht mehr im Detail zu überwachen und in Innovationen zu investieren – ohne riesige Budgets.
Qualität, die überrascht
Trotz seines leichtgewichtigen Designs behauptet Google, dass Flash-Lite ältere 2.0-Modelle in mehreren Bereichen übertrifft – beim Denken, Codieren, multimodalen Verstehen und sogar bei Audio- und Bildaufgaben.
Großes Kontextfenster
Flash-Lite behält das Gemini-Kontextfenster mit einer Million Token bei, d. h. es kann sehr lange Dokumente, Protokolle oder Codebases verarbeiten, ohne dass die Kohärenz verloren geht.
Flexibel denken Budget
Die Entwickler können die „Denktiefe“ des Modells individuell anpassen, indem sie bei Bedarf eine erweiterte Argumentation anwenden und gleichzeitig an anderer Stelle Ressourcen einsparen – ein ausgewogenes Verhältnis zwischen Leistung und Kosten.
🔬 Hinter der Technik
Flash-Lite baut auf der Gemini 2.5-Architektur auf, indem es Echtzeit-Denken und Tool-Integrationen an ein effizienteres Parameter-Budget weitergibt. Es unterstützt multimodale Eingaben (Text, Bild, Audio, Video), 1M-Token-Kontext und Thinking-Budgets – alles bei geringer Latenz und niedrigen Kosten.
Flash-Lite lässt sich über die Google-Suche, die Live-Code-Ausführung und den URL-Kontext nahtlos in Grounding einbinden und bietet intelligentes, kontextbezogenes Reasoning ohne teuren Overhead.
🏗 Praktische Anwendungsfälle
Die ersten Anwender setzen Gemini 2.5 Flash-Lite bereits in anspruchsvollen, realen Szenarien ein:
Satlyt (Satellitendiagnostik)
Das Raumfahrt-Startup Satlyt konnte die Latenzzeit bei der Onboard-Diagnose um 45 % und den Stromverbrauch um 30 % senken, indem es Flash-Lite einsetzte – ein entscheidender Fortschritt, bei dem jedes Watt und jede Sekunde zählen.
HeyGen (Video-Übersetzung)
HeyGen nutzt das Modell, um die Erstellung von Videoskripten und die Übersetzung in mehr als 180 Sprachen zu automatisieren und so eine globale Bereitstellung von Inhalten in großem Umfang zu ermöglichen.
DocsHound (Extraktion von Dokumentation)
Durch die Verarbeitung langer Lehrvideos mit Flash-Lite extrahiert DocsHound schnell relevante Screenshots und Zusammenfassungen und beschleunigt so die Erstellung technischer Dokumentationen.
Evertune (Markenanalyse)
Evertune setzt Gemini ein, um KI-generierte Inhalte nach Markenerwähnungen und Stimmungen zu scannen und bietet so schnelle Einblicke in große Datensätze.
Diese Beispiele zeigen, dass Flash-Lite in der Lage ist, multimodale Aufgaben mit hohem Volumen und in Echtzeit durchzuführen, die zuvor zu kostspielig oder zu langsam waren.
📊 Preisgestaltung und Verfügbarkeit für Entwicklerfreundlichkeit
Bildquelle: Google
| Verwendung | Preis pro 1M Token |
| Text-/Bild-/Videoeingabe | $0.10 |
| Audio-Eingang | $0.30 |
| Output (Denken) | $0.40 |
| Kontext-Caching-Speicher | $0.025/hr |
Hinweis: Die Preisvorschau endet am 25. August 2025, daher sollten Entwickler auf die gemini-2.5-flash-lite Modell-ID aktualisieren.
Flash-Lite ist in Google AI Studio und Vertex AI verfügbar und ermöglicht eine nahtlose Bereitstellung über API oder Plattform.
🧭 Wann sollte man Flash-Lite wählen?
Wählen Sie Gemini 2.5 Flash-Lite, wenn Sie:
- Sie benötigen Echtzeit-Reaktionsfähigkeit, z. B. Chatbots oder Live-Dolmetschen.
- Sie arbeiten mit umfangreichen Verarbeitungen wie Transkripten oder Protokollen und müssen die Kosten kontrollieren.
- Sie benötigen multimodale Eingaben wie Text, Bild, Audio oder Video.
- Sie möchten eine Feinabstimmung der Argumentationsebenen vornehmen und ein Gleichgewicht zwischen Geschwindigkeit und Tiefe pro Aufgabe herstellen.
Für umfangreichere Argumentationsaufgaben, komplexe Codegenerierung oder tiefgreifende Analysen ist Gemini 2.5 Flash oder Pro möglicherweise besser geeignet – allerdings zu höheren Kosten.
🌐 Auswirkungen auf den Markt: Intelligenz pro Dollar
Flash-Lite senkt die Hürden für fortgeschrittene KI erheblich, insbesondere für:
- Startups und NGOs mit knappen Budgets
- Kleine Teams und Einzelentwickler, die MVPs entwickeln
- Bildungstools, die skalierbare und dennoch erschwingliche KI benötigen
- Unternehmen, die Anwendungsfälle mit hohem Volumen über mehrere Plattformen hinweg einsetzen
Diese Verschiebung fällt mit allgemeinen KI-Kostenproblemen zusammen – ein Echo auf Googles frühere Bemühungen in 2.0 Flash-Lite, erschwingliche, leistungsfähige Modelle unter wirtschaftlichem Druck anzubieten.
🔜 Tipps für den Einstieg
- Aktualisieren Sie auf Stable: Ersetzen Sie vor dem 25. August alle Verweise auf das Vorschaumodell durch gemini-2.5-flash-lite.
- Setzen Sie Denkbudgets: Passen Sie die Denktiefe für jede Aufgabe an – weniger für einfache Abfragen, mehr für komplexe Überlegungen.
- Aktivieren Sie Tools: Verwenden Sie Grounding, Code Execution und URL Context, um die Intelligenz zu steigern.
- Implementieren Sie Context Caching: Speichern Sie wiederkehrenden Prompt-Kontext, um Kosten und Latenzzeiten um bis zu 75 % zu reduzieren.
🔚 Abschließendes Fazit
Gemini 2.5 Flash-Lite wird im Jahr 2025 zum suitableimmenden Modell, das fortschrittliche, multimodale KI mit blitzschneller Geschwindigkeit, tiefem Kontext und unschlagbarer Kosteneffizienz bereitstellt. Praktische Anwender wie Satlyt, HeyGen und DocsHound sind bereits ein Beweis für den Wert dieser Technologie. Egal, ob Sie ein Startup, eine Bildungseinrichtung, ein Unternehmen oder ein Einzelentwickler sind, mit Flash-Lite können Sie leistungsstarke KI entwickeln, ohne die Bank zu sprengen.
Wenn Sie auf skalierbare, multimodale Echtzeitanwendungen abzielen, ist Gemini 2.5 Flash-Lite Ihr neues Arbeitspferd schlechthin. Es verspricht nicht nur „Intelligenz pro Dollar“ – es liefert sie auch.
✅ FAQ
F: Was ist Gemini 2.5 Flash-Lite?
A: Die schnellste, günstigste Gemini 2.5-Variante von Google ist für kosteneffiziente Echtzeit-KI-Aufgaben mit multimodaler Unterstützung und 1-Millionen-Token-Kontext optimiert.
F: Wie viel kostet es?
A: $0,10 pro Million Input-Token, $0,40 pro Output. Audio kostet $0,30 Eingabe. Kontext-Caching kostet 0,025 $/Std.
F: Ist es für Live-Anwendungen geeignet?
A: Flash-Lite reduziert die Latenzzeit im Vergleich zu früheren Flash-Modellen stark, ideal für Chats, Übersetzungen und Live-Analysen.
F: Welche Aufgaben kann es erfüllen?
A: Hervorragend geeignet für Codierung, logisches Denken, multimodale Aufgaben und die Verarbeitung langer Kontexte – und das zu einem erschwinglichen Preis.