Google recently launched the stable version of Gemini 2.5 Flash‑Lite, designed as a performance-optimized, budget-friendly workhorse for developers building AI-driven tools at scale. This model aims to deliver great value—smart, fast, and affordable—making it ideal for real-time apps and cost-conscious teams.
⚙️ Why Gemini 2.5 Flash‑Lite Matters
1. Speed for Real‑Time Experiences
Google positions Flash‑Lite as its fastest 2.5-series model, reporting significantly lower latency than previous versions like 2.0 Flash and 2.0 Flash‑Lite. This responsiveness makes it Suitable for live translation, chatbots, and time-sensitive interactions where even sub-second delays can frustrate users.
2. Elite Value
At just $0.10 per million input tokens and $0.40 per million output tokens, Flash‑Lite offers exceptional “intelligence per dollar.” This pricing enables developers to stop micromanaging API call usage and invest in innovation—without colossal budgets.
3. Quality That Surprises
Despite its lightweight design, Google claims Flash‑Lite outperforms older 2.0 models across multiple domains—reasoning, coding, multimodal understanding, even on audio and image tasks.
4. Massive Context Window
Flash‑Lite retains Gemini’s one-million-token context window, meaning it can handle very long documents, transcripts, or codebases without losing coherence.
5. Flexible Thinking Budget
Developers can tailor the model’s “thinking” depth, applying enhanced reasoning when needed while conserving resources elsewhere—a balance between performance and cost.
🔬 Behind the Technology
Flash‑Lite builds on the Gemini 2.5 architecture by passing real-time thinking and tool integrations to a more efficient parameter budget. It supports multimodal input (text, image, audio, video), 1M-token context, and thinking budgets—all while delivering low latency and low cost.
Flash‑Lite also integrates seamlessly with Grounding via Google Search, live code execution, and URL context, offering smart, contextual reasoning without expensive overhead.
🏗 Real‑World Use Cases
Early adopters are already deploying Gemini 2.5 Flash‑Lite in demanding, real-world scenarios:
• Satlyt (Satellite Diagnostics)
A space-tech startup, Satlyt, reduced onboard diagnostic latency by 45% and cut power use by 30% using Flash‑Lite—critical gains where every watt and second count.
• HeyGen (Video Translation)
HeyGen uses the model to automate video scripting and translation across 180+ languages, enabling global content delivery at scale.
• DocsHound (Documentation Extraction)
By processing long instructional videos with Flash‑Lite, DocsHound quickly extracts relevant screenshots and summaries—accelerating the creation of technical documentation.
• Evertune (Brand Analytics)
Evertune applies Gemini to scan AI-generated content for brand mentions and sentiment, offering fast insights across large datasets.
These examples show Flash‑Lite’s capability to power high-volume, real-time, multimodal tasks that were previously too costly or slow.
📊 Developer-Friendly Pricing & Availability
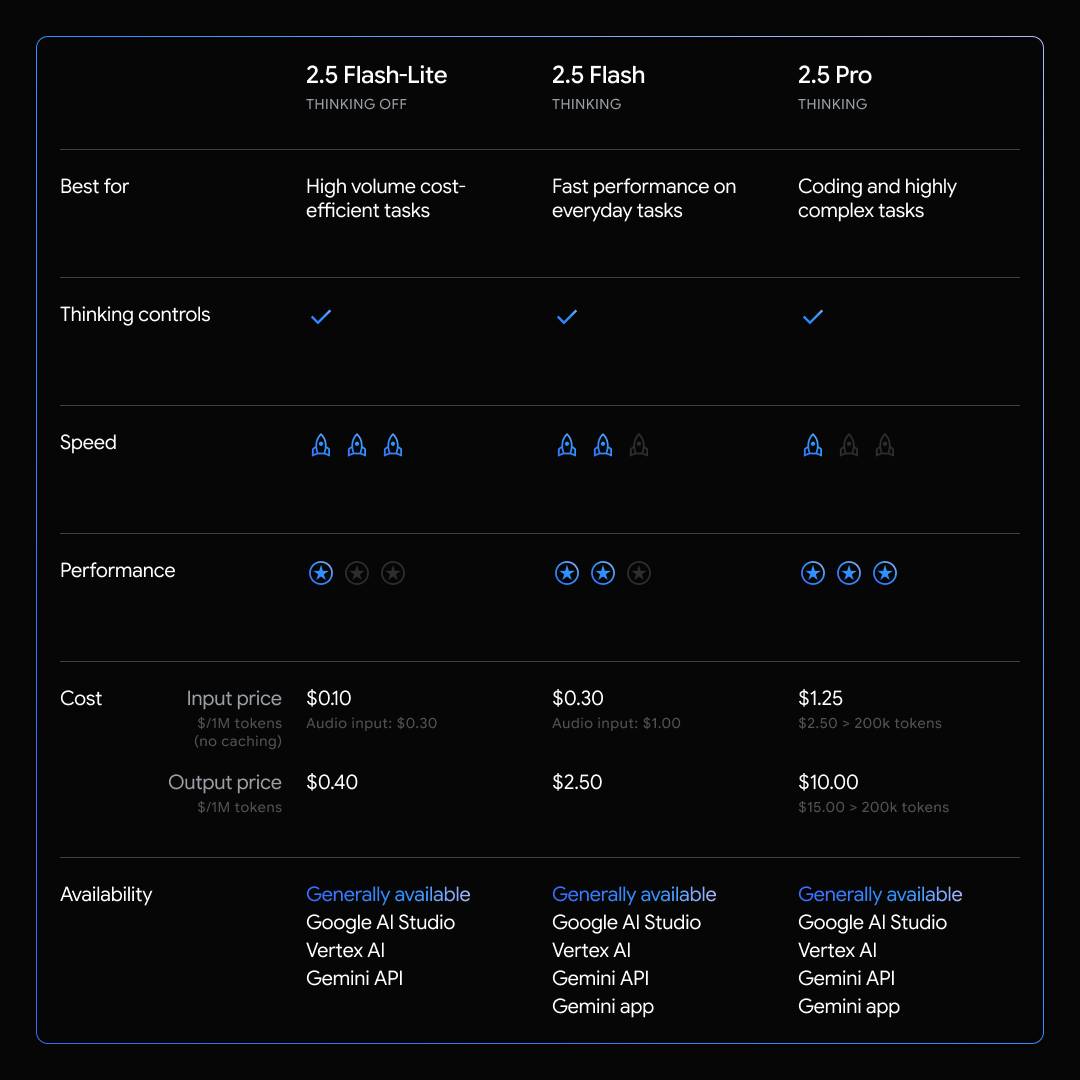
Image Source: Google
| Usage | Price per 1M Tokens |
| Text/Image/Video Input | $0.10 |
| Audio Input | $0.30 |
| Output (thinking) | $0.40 |
| Context Caching Storage | $0.025/hr |
Note: Preview pricing ends August 25, 2025, so developers should update to the gemini-2.5-flash-lite model ID.
Flash‑Lite is available in Google AI Studio and Vertex AI, making deployment via API or platform seamless.
🧭 When to Choose Flash‑Lite
Choose Gemini 2.5 Flash‑Lite when you:
- Need real-time responsiveness, e.g., chatbots or live interpretation.
- Work on large-scale processing like transcripts or logs and must control costs.
- Require multimodal inputs including text, image, audio, or video.
- Want to fine-tune reasoning levels, balancing speed and depth per task.
For heavier reasoning tasks, complex code generation, or in-depth analysis, Gemini 2.5 Flash or Pro may be a better fit—though at higher cost.
🌐 Market Impact: Intelligence per Dollar
Flash‑Lite significantly lowers barriers to advanced AI, particularly for:
- Startups and NGOs on tight budgets
- Small teams and solo developers building MVPs
- Educational tools needing scalable yet affordable AI
- Enterprises deploying high-volume use cases across multiple platforms
This shift coincides with broader AI cost concerns—echoing Google’s previous efforts in 2.0 Flash‑Lite to offer affordable, performant models under economic pressure.
🔜 Getting Started Tips
- Upgrade to Stable: Replace any preview model references with gemini-2.5-flash-lite before August 25.
- Set Thinking Budgets: Adjust thought depth for each task—less for simple queries, more for complex reasoning.
- Enable Tools: Use Grounding, Code Execution, and URL Context to enhance intelligence.
- Implement Context Caching: Save recurring prompt context to reduce charges and latency by up to 75%.
🔚 Final Takeaway
Gemini 2.5 Flash‑Lite emerges as a defining model in 2025—delivering advanced, multimodal AI with lightning speed, deep context, and unbeatable cost efficiency. Real-world adopters like Satlyt, HeyGen, and DocsHound are already proof of its value. Whether you’re a startup, educator, enterprise, or solo developer, Flash‑Lite makes it possible to build powerful AI without breaking the bank.
If you’re targeting scalable, real-time, multimodal applications, Gemini 2.5 Flash‑Lite is your new go-to workhorse. It doesn’t just promise “intelligence per dollar”—it delivers it.
✅ FAQ
Q: What is Gemini 2.5 Flash‑Lite?
A: It’s Google’s fastest, most affordable Gemini 2.5 variant—optimized for real-time, cost-effective AI tasks, with multimodal support and a 1M-token context.
Q: How much does it cost?
A: $0.10 per million input tokens, $0.40 per output. Audio costs $0.30 input. Context caching is $0.025/hr.
Q: Is it suitable for live apps?
A: Yes—Flash‑Lite reduces latency dramatically versus earlier Flash models, ideal for chat, translation, and live analysis.
Q: What tasks can it perform?
A: Excellent for coding, reasoning, multimodal tasks, and long context processing—while staying affordable.